A revolutionary and holistic approach to software reliability that incorporates performance insights right from the start of the application lifecycle, all the way through to the continuous optimization of system reliability with proactive monitoring of Service Level Objectives (SLO) in Production.
Everything you need for game-changing SRE excellence in a single intelligent, no-code platform.
Adopt a shift-left approach to SRE that empowers your engineering teams with valuable performance insights when they need to make critical decisions on architecture design and functionality development.
Functional and API testing can be complex and highly skills-dependent. Eliminate inconsistencies with automated, AI-driven testing that requires zero-coding skills and can be utilised by various personas ,such as Developers, Business Analysts, Manual Testers, Automation Testers, and Business Users, making for a much more robust experience.
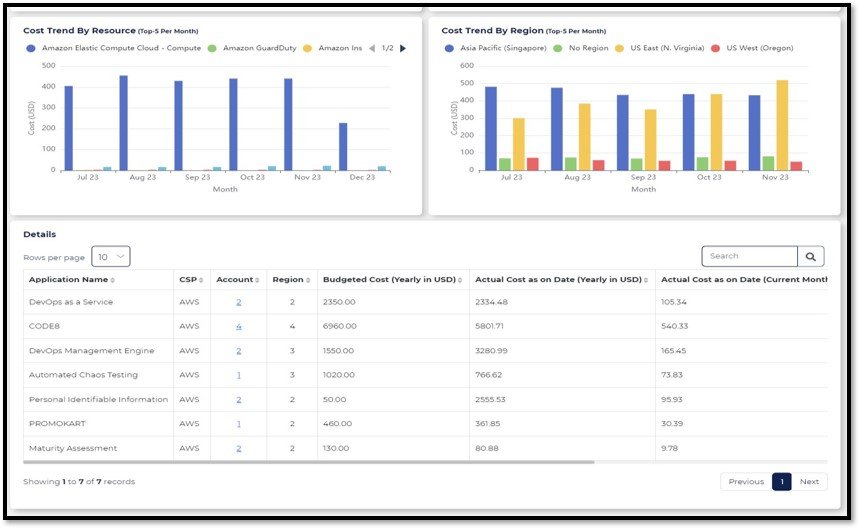
Enhance visibility of undercurrents to better gauge reliability sensitivity to change releases. With continuous measurement of Service Level Indicators in place, your team will have the data they need to make critical release decisions without compromising on system stability.
Uncover system weakness and test complex business journeys early on in the software lifecycle with chaos engineering to allow for proactive remediation. This sets the gold standard for reliability and ensures an excellent customer experience.
A no-code, AI-driven testing module that tackles common testing challenges and enhances the testing process with a focus on reliability, by incorporating cutting-edge Observability Driven Testing concepts. It’s a game-changer in ensuring software excellence across Web, Mobile, Desktop and Legacy applications.

(SRE) is a discipline that incorporates aspects of software engineering and
applies them to infrastructure and operations problems. It focuses on building
reliable and scalable systems through automation and engineering practices.
The traditional approach to SRE involves an approach from a infrastructure lens.
This is to ensure that there is a benchmark for reliability and performance, guiding engineering efforts and prioritizing improvements.
With fast evolving complex eco-systems the definition above has also evolved.
Fundamentally SRE stems from the following key points:
Service Level Indicators (SLIs): Metrics used to quantify the performance and reliability of a service such as latency, error rate, throughput, availability, etc.
Service Level Objectives (SLOs): Setting explicit reliability targets based on Service Level Indicators (SLIs) to measure system performance, for example:
Automation: This therefore leads into emphasis to automate repetitive tasks and processes to reduce manual intervention and human error.
Operational Efficiency: The outcome of this should also lead to operate systems effectively with minimal waste of resources.
Today, evolving SRE platforms are expected to also include:
Autonomous API Testing with increasing demands on SOA there is also a wide gap to be filled with testing that is completely created, driven, and managed by AI/ML or automation technologies, eliminating the need for human intervention.
Chaos Engineering Though the roots of Chaos Engineering, can be traced as far back as Apple in 1983, realistically this definition was crafted appropriately when Netflix introduced it in their eco-system.
Today, the demands for Chaos Engineering is much needed across multiple platforms – on-premise systems, Kubernetes, OpenShift, AWS and Azure